📚 이 글은 ‘AI 도입 인사이트’ 시리즈의 일부입니다. ▶ 시리즈 전체 보기 →
요즘 많은 중소기업들이 AI를 도입하려는 시도를 하고 있습니다. 자동화, 예측 분석, 고객 인사이트 도출 등 다양한 이유로 AI에 대한 관심은 높아지고 있지만, 실질적으로 성과를 낸 사례는 아직 많지 않습니다. 왜일까요? 정답은 단순합니다. 대부분의 기업들이 '데이터'를 준비하지 않은 채 기술만 도입하려 하기 때문입니다.
AI는 마법이 아닙니다. 정확하고 신뢰할 수 있는 데이터를 바탕으로만 의미 있는 결과를 도출할 수 있습니다. 특히 중소기업은 제한된 리소스를 가지고 있기 때문에, 잘못된 데이터로부터 잘못된 결론을 내리면 손실이 매우 커질 수 있습니다. 그래서 이 글에서는 'AI 도입 전 데이터 정제의 중요성'을 구체적인 사례와 실전 팁을 통해 풀어보려 합니다.
목차
왜 AI 이전에 데이터 정제가 먼저인가?
데이터 정제란 무엇인가? 실무 정의와 범위
데이터 정제가 AI 성능에 미치는 실제 영향
중소기업에서 데이터 정제, 현실적으로 어떻게 할 수 있나?
결론 및 추천: 데이터가 AI의 연료라면, 정제는 정비다
FAQs
왜 AI 이전에 데이터 정제가 먼저인가?
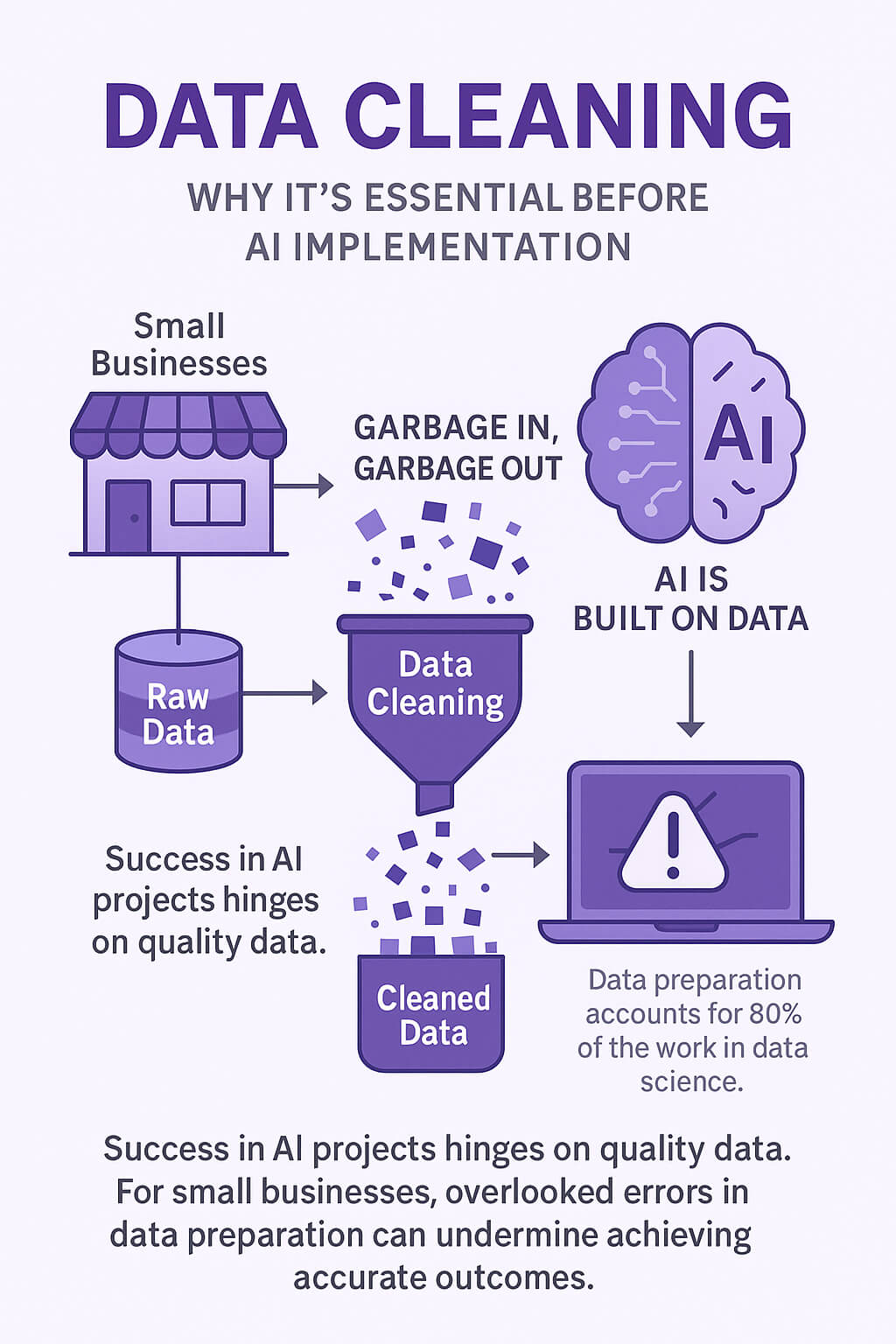
여러분은 AI를 도입하기 전에 어떤 준비가 필요하다고 생각하시나요? 많은 기업들이 알고리즘과 모델 선택에 집중하지만, 실제 AI 프로젝트의 성공 여부는 데이터 품질에 좌우됩니다. 특히 중소기업은 제한된 리소스를 고려했을 때, 데이터 준비단계에서 실수가 반복되면 전체 프로젝트의 방향이 흔들릴 수 있습니다.
데이터 정제는 AI 프로젝트의 기반을 다지는 과정입니다. 비유하자면, 오염된 연료로는 아무리 좋은 엔진도 제 성능을 낼 수 없습니다. 예를 들어, 고객 행동 예측을 위한 모델을 만들려 할 때, 고객 이름이 중복되거나, 구매 일시가 누락된 상태라면 모델은 왜곡된 판단을 하게 됩니다.
이런 이유로 데이터 정제는 단순한 사전 작업이 아니라, AI 시스템의 정확도와 신뢰도를 좌우하는 핵심 단계입니다. IBM은 "데이터 준비에 전체 데이터 사이언스 프로젝트 시간의 80%가 사용된다"라고 보고한 바 있습니다(IBM, 2021). 즉, 이 단계를 소홀히 하면 이후 과정은 무너질 수밖에 없습니다.
데이터 정제란 무엇인가? 실무 정의와 범위
데이터 정제(Data Cleaning)는 수집된 데이터에서 오류, 불일치, 결측값, 중복 등을 식별하고 수정하는 일련의 과정을 말합니다. 이는 단순한 데이터 삭제가 아니라, 데이터의 신뢰성과 일관성을 확보하기 위한 '정비 작업'이라 할 수 있습니다.
실무적으로는 다음과 같은 항목이 포함됩니다: ① Null 또는 결측값 처리, ② 잘못된 형식(예: 날짜, 숫자 오류) 수정, ③ 중복 데이터 제거, ④ 범주값 통일(예: '남', '남성', 'M'을 모두 '남성'으로 정리), ⑤ 이상치 탐지 및 처리입니다. 이 과정은 엑셀 수준의 간단한 정제부터, Python의 Pandas, OpenRefine, Trifacta 같은 도구를 활용한 자동화까지 다양하게 이뤄질 수 있습니다.
중소기업이라면 처음에는 Google Sheets의 "Data Cleanup" 기능이나, 무료 오픈소스 툴을 적극 활용하는 것이 좋습니다. 규모가 커질수록 전문적인 파이프라인이 필요하겠지만, 처음부터 거대한 시스템을 구축하는 것은 오히려 리스크가 될 수 있습니다.
데이터 정제가 AI 성능에 미치는 실제 영향
많은 기업들이 AI 모델의 정확도가 낮을 때, 알고리즘을 바꾸거나 더 복잡한 모델을 시도합니다. 하지만 데이터 품질이 낮다면 어떤 모델도 좋은 결과를 내기 어렵습니다. 캐글(Kaggle) 등의 대회에서도 "정제된 데이터가 모델을 이긴다"는 말이 있을 정도입니다.
예를 들어, 고객 이탈 예측 모델에서 나이 값이 잘못 입력된 사례를 봅시다. 150세나 -5세 같은 값이 포함되어 있다면, 이 데이터는 평균값 계산에 왜곡을 주고, 결과적으로 예측의 정확도를 크게 떨어뜨립니다. 이런 문제는 모델링 이후에 발견되면 수정이 매우 어렵습니다.
Meta(구 Facebook)는 데이터 정제 후 모델 정확도가 평균 7~15% 향상된다고 보고한 바 있으며(출처:Meta AI Research, 2022), 국내 기업들도 파일럿 테스트에서 비슷한 향상폭을 경험하고 있습니다. 즉, 모델의 성능 향상은 알고리즘이 아니라, 데이터 정제에서 출발하는 셈입니다.
많은 기업들이 Copilot이나 자동화 도구를 도입할 때, 데이터 정제 단계를 생략해 실패를 겪습니다. AI 도입 실패의 주요 원인을 정리한 AI 도입이 실패하는 5가지 이유 글도 함께 참고해 보세요.
중소기업에서 데이터 정제, 현실적으로 어떻게 할 수 있나?
그렇다면 인력도 예산도 제한된 중소기업은 어떻게 데이터 정제를 시작해야 할까요? 첫 번째로는 '데이터 정제의 우선순위'를 정해야 합니다. 모든 데이터를 한 번에 정제하는 것은 비효율적일 수 있으므로, AI 모델에 가장 큰 영향을 주는 핵심 칼럼부터 정제하는 전략이 필요합니다.
두 번째는 자동화 도구 활용입니다. 앞서 언급한 OpenRefine, Talend Data Prep, Google DataPrep 같은 도구는 비개발자도 GUI 기반으로 정제 작업을 할 수 있도록 도와줍니다. 또한 Python의 Pandas 라이브러리는 중급 이상의 사용자에게 강력한 도구가 될 수 있습니다.
마지막으로 중요한 것은 '정제 기록'입니다. 어떤 데이터를 어떻게 정제했는지 기록하지 않으면, 동일한 문제가 반복되거나, 향후 오류의 원인을 추적하기 어렵습니다. 이 때문에 데이터 정제 프로세스를 '재현 가능한 설계'로 만드는 것이 중요합니다. 이 점은 결국 데이터 거버넌스의 출발점이기도 합니다.
결론 및 추천: 데이터가 AI의 연료라면, 정제는 정비다
데이터는 AI의 연료입니다. 하지만 정제되지 않은 연료는 시스템을 망가뜨릴 수 있습니다. AI의 성공 여부는 멋진 기술보다, 얼마나 잘 준비된 데이터로 시작하느냐에 달려 있습니다. 특히 중소기업은 적은 리소스로 최대 효과를 보기 위해, '모델보다 데이터'를 우선시하는 전략이 필요합니다.
그래서 지금 여러분들이 해야 할 일은, 현재 가지고 있는 데이터에서 무엇이 가장 중요한지를 식별하고, 그 데이터를 정제하는 작은 실천부터 시작하는 것입니다. 정제는 단기 ROI가 보이지 않을 수 있지만, AI 프로젝트 전체의 지속 가능성과 직접 연결되어 있다는 점을 꼭 기억해 주세요. 지금 바로 실천해 보세요!
FAQs
아닙니다. 초기 단계에서는 엑셀, Google Sheets, 무료 툴로도 충분히 시작할 수 있습니다. 중요한 것은 프로세스를 기록하고 일관되게 반복하는 것입니다.
AI 모델에서 주요 입력값으로 사용되는 칼럼부터 정제하는 것이 효과적입니다. 예: 고객 정보, 구매 이력 등.
가능합니다. Python, Talend, Google DataPrep 등 다양한 자동화 툴이 존재하며, 반복 작업을 줄일 수 있습니다.
기술적으로는 가능합니다. 하지만 정확도와 신뢰도가 떨어지며, 모델 편향과 위험 요소가 증가합니다.
다음 글 : 2025년 중소기업용 AI SaaS 트렌드 Top 5 →
📌 SEO 콘텐츠 정보
- 카테고리: AI·기술 트렌드
- 시리즈명: AI 도입 인사이트
- 개별 글 제목: AI 도입 전, 데이터 정제는 얼마나 중요한가?
- 키워드: 본문 태그와 동일
- 작성일: 2025-05-29
본 콘텐츠는 정보 제공을 목적으로 하며, 특정 국가나 기업에 대한 편향 없이 작성되었습니다.
'AI·기술 트렌드 & 산업 변화' 카테고리의 다른 글
| AI 생산성 도구 vs 인간 업무 효율: 진짜 절감 효과는? (0) | 2025.05.31 |
|---|---|
| 2025년 중소기업용 AI SaaS 트렌드 Top 5 (0) | 2025.05.30 |
| AI 도입이 실패하는 5가지 이유 (0) | 2025.05.28 |
| AI + ERP 시스템, 어떻게 통합되고 있나? (0) | 2025.05.27 |
| 중소기업도 생성형 AI를 쓸 수 있을까? (0) | 2025.05.26 |



